
Une étude menée sur des ingénieurs chevronnés montre que l’IA générative, loin de les booster, augmente leur temps de travail comme le révèle Next. Une remise en question nécessaire des discours optimistes sur la productivité artificielle.
Une promesse largement contredite par les faits
L’IA générative devait transformer la productivité des développeurs. Accélérer l’écriture de code, éliminer les erreurs, fluidifier les tâches répétitives. Pourtant, une étude du laboratoire METR jette un froid : les développeurs testés sont 19 % plus lents avec IA que sans. Une contre-performance d’autant plus marquante qu’elle contredit à la fois les prédictions des experts… et la perception des participants eux-mêmes.
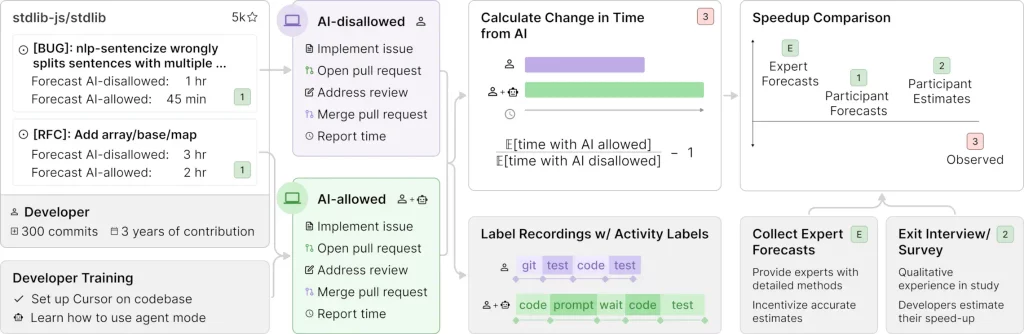
Ce résultat provient d’un essai contrôlé randomisé mené début 2025 auprès de 16 développeurs expérimentés, habitués à travailler sur des projets open source majeurs. Loin d’une simple démonstration académique, il interroge les usages réels des outils comme Cursor Pro ou Claude 3.5/3.7 Sonnet, et la manière dont les professionnels intègrent (ou non) l’IA dans leur flux de travail.
Un protocole réaliste, centré sur des tâches complexes
Contrairement aux benchmarks habituels, souvent trop abstraits ou trop simplifiés, METR a conçu un protocole proche du terrain. Les développeurs ont travaillé sur 246 tâches réelles – bugs, refontes ou ajouts de fonctionnalités – issues de leurs propres dépôts GitHub. Chacune d’entre elles a été aléatoirement assignée à une condition avec ou sans IA.
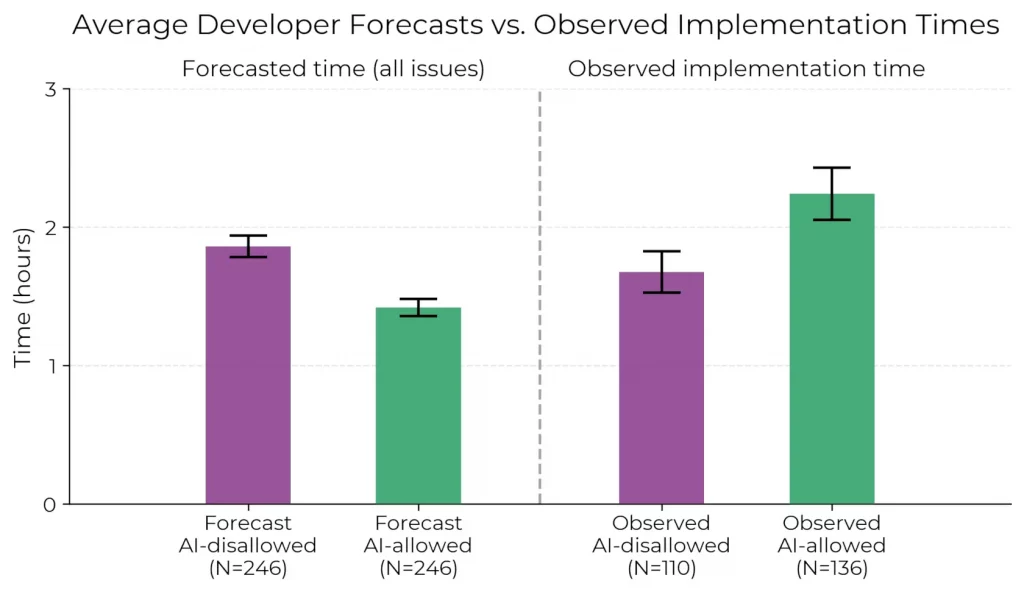
Résultat : malgré leur liberté d’outil et leur expérience (plus de dix ans de pratique en moyenne), les participants ont mis plus de temps à résoudre les problèmes quand ils utilisaient des assistants d’IA. L’écart est particulièrement visible sur les tâches longues (1 à 6 heures), où la performance chute nettement.
Les développeurs… ne s’en rendent même pas compte
Le plus surprenant ? Même après avoir été ralentis, les développeurs continuent de croire que l’IA les aide. Avant l’étude, ils anticipaient un gain de productivité de 24 %. Après l’étude, malgré des résultats mesurés inverses, ils l’estiment encore à +20 %. Ce biais de perception met en lumière l’écart croissant entre expérience vécue et résultat objectif, et renforce l’importance de méthodes rigoureuses pour évaluer les outils.
Pourquoi l’IA ralentit-elle les plus expérimentés ?
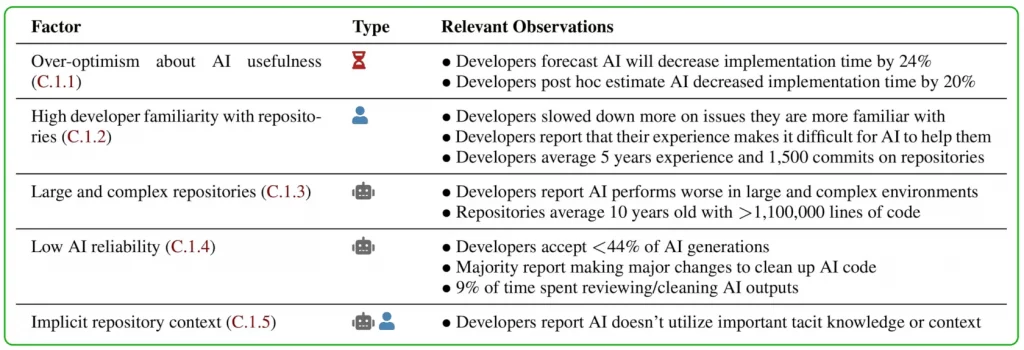
METR avance plusieurs pistes : surcharge cognitive, détours exploratoires, surconfiance dans les suggestions de l’IA, ou encore exigences implicites (tests, documentation, qualité de code) que l’IA ne gère pas bien. Le ralentissement n’est pas dû à une mauvaise implémentation : les développeurs ont utilisé les meilleurs modèles du moment, dans des conditions optimales. Ce sont bien les limites actuelles des outils qui sont pointées ici.
Autre facteur important : le niveau d’exigence. Sur des dépôts hautement qualitatifs, un code correct ne suffit pas : il faut qu’il soit lisible, documenté, testé, formaté. L’IA peut générer une solution plausible, mais pas toujours une solution acceptable pour une relecture sérieuse.
Pourquoi les benchmarks et les anecdotes nous induisent en erreur
Les résultats de METR s’opposent aux scores impressionnants des benchmarks comme SWE-Bench ou RE-Bench. La différence tient à la nature des tâches évaluées. Les benchmarks privilégient des tests autonomes, facilement scorables, avec peu de contexte. L’étude de METR, elle, s’ancre dans la réalité du développement logiciel, avec ses contraintes humaines, son histoire de projet, ses normes implicites.
Même constat pour les anecdotes enthousiastes relayées en ligne : elles reposent sur des impressions, souvent biaisées, et des contextes plus permissifs. Une tâche jugée “aidée par l’IA” peut en réalité avoir été ralentie sans que son auteur ne s’en rende compte.
L’IA peut-elle encore tenir ses promesses ?
METR ne ferme pas la porte à des améliorations futures. L’étude ne dit pas que l’IA est inutile, mais qu’elle ralentit aujourd’hui les développeurs expérimentés dans des contextes exigeants. Il est possible que de nouveaux usages, une meilleure intégration ou des heures d’entraînement supplémentaires inversent la tendance. Mais pour l’instant, la promesse d’un gain de productivité universel reste largement surévaluée.