Sapphire Rapids : une expérience directe avec les accélérateurs Xeon de 4e génération d’Intel.

Il n’y a pas si longtemps, nous avons eu notre première expérience avec les Xeon scalables de 4ème génération d’Intel, nom de code Sapphire Rapids, et nous avons vérifié quelques benchmarks en direct. Lors de la démonstration, Intel a confronté son silicium de préversion au meilleur processeur actuel d’AMD, un serveur équipé d’une paire de processeurs 64 cœurs EPYC 7763 basés à Milan, et les diverses technologies d’accélération de l’équipe bleue ont remporté victoire sur victoire dans certaines charges de travail courantes. Le serveur Intel était doté d’une paire de processeurs à 60 cœurs avec accélération QAT (Quick Assist Technology) et d’un téraoctet complet de RAM. Cette machine monstrueuse est le genre de machine qu’Intel s’attend à voir entreposée dans les centres de données, poussant l’enveloppe des performances dans diverses charges de travail de serveurs et de cloud computing.
Non content de les montrer dans un environnement contrôlé, Intel nous a offert la possibilité de mettre nous-mêmes la main sur l’un de ces serveurs monstrueux. Lorsque FedEx a livré le châssis 2U montable en rack avec la même configuration que lors de notre rencontre en personne, nous avons pu recréer l’expérience de test du centre de données d’Intel dans notre propre laboratoire, avec des tonnes de puissance, des ventilateurs hurlants et des écouteurs antibruit pour nous tenir compagnie.
Malheureusement, nous ne pouvons pas divulguer beaucoup plus de détails sur ce système ; étant donné son statut de pré-production, Intel n’est pas encore tout à fait prêt à annoncer les numéros de modèle, les configurations de cache, les vitesses de cœur, etc. Nous allons certainement honorer cette demande mais ne vous inquiétez pas, tout sera révélé en temps voulu. La bonne nouvelle, c’est que nous avons pu effectuer des tests qui ne faisaient pas partie de notre démonstration initiale, et Intel nous a permis de partager ces résultats avec vous ici aussi.
Configuration d’un serveur Xeon Intel Sapphire Rapids
Nous avons vu des fuites et nous avons vu ces processeurs en personne, mais les véritables preuves se trouvent dans l’exécution de benchmarks par nous-mêmes. L’aspect amusant de l’expérience pratique d’Intel est que le serveur que nous avons reçu n’avait pas de système d’exploitation. Comme pour prouver qu’il n’y a pas de configuration logicielle magique, la société a fourni des instructions étape par étape pour reproduire ses résultats par nous-mêmes. Nous avons pu installer Ubuntu 22.04 et CentOS Stream 8, cloner les dépôts Git disponibles publiquement et exécuter tous les tests que nous avons vus en personne en septembre à Intel Innovation. Bien que l’installation d’un système d’exploitation à partir de zéro ne soit pas la tâche la plus glamour, nous savons que notre configuration logicielle sera la même pile disponible publiquement que celle utilisée par le reste du monde. Cela signifie que les résultats des benchmarks que nous fournissons ci-dessous devraient être indicatifs des performances attendues par Intel dans les déploiements réels.
Nous avons commencé avec la dernière version LTS (long-term supported) d’Ubuntu Server, 22.04, et à part l’activation de SSH et l’installation des pilotes pour la paire de cartes 100-Gigabit Ethernet, il n’y a pas eu de configuration supplémentaire. Certains des tests présentés par Intel nécessitent du matériel client supplémentaire, et les clients étaient plus puissants que ce que nous avons sous la main.
C’est pourquoi Intel nous a donné un accès à distance à une paire client/serveur, et nous avons pu d’abord confirmer le matériel et le logiciel installés sur chacun et reproduire ces tests à distance. Ce n’est pas tout à fait la même chose que de les exécuter dans nos bureaux, mais nous étions à l’aise avec ce compromis. Les tests NGINX, SPDK et IPSec que vous verrez bientôt ont donc été réalisés de cette manière.

Dans le cadre du processus de configuration du benchmark, Intel a fourni des scripts spécifiques, des instructions étape par étape et les paramètres BIOS recommandés pour chaque test. Entre chaque test, nous avons installé les logiciels requis, configuré le BIOS si nécessaire et redémarré le système. Chaque test a été effectué trois fois, et nous avons pris le résultat médian pour chaque tâche pour nos résultats graphiques ci-dessous. La configuration de notre système de test était identique à celle qu’Intel a présentée en septembre, les résultats devraient donc être les mêmes, si tout se passe comme prévu.
Pour référence, les spécifications de notre système sont les suivantes : 2x processeurs Intel Xeon Scalable de 4ème génération (60 cœurs) de pré-production avec Intel Advanced Matrix Extensions (Intel AMX), sur une plateforme et un logiciel Intel de pré-production avec 1024GB de mémoire DDR5 (16x64GB), microcode 0xf000380, HT On, Turbo On, SNC Off. Les paramètres du BIOS dépendaient principalement de la nécessité ou non de la virtualisation pour chaque tâche, et celle-ci était donc activée et désactivée selon les besoins.

Nouveaux benchmarks pour les Intel Sapphire Rapids Xeon de 4ème génération
Avant d’aborder les tests effectués à distance, il y a quelques charges de travail que nous n’avons pas encore vu fonctionner avec Sapphire Rapids, alors commençons par celles-ci. Tout d’abord, LINPACK, que nous avons testé en utilisant la version optimisée d’Intel basée sur ses bibliothèques mathématiques oneAPI. Nous avons pu tester à la fois avec un codepath AVX2 et AVX512.
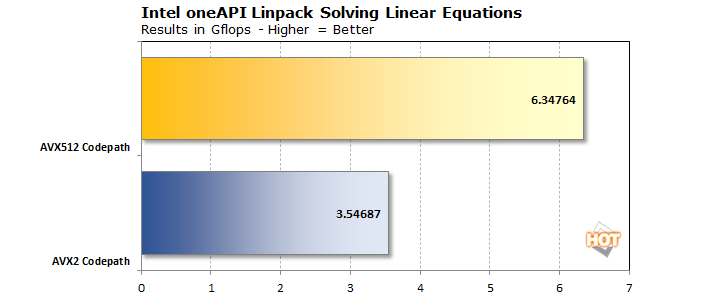
Comme vous pouvez le voir, la version AVX512 est environ 90% plus rapide que la version AVX2. Non pas que 3,5 téraflops avec AVX2 soit une réussite, mais avec les extensions d’AVX512, la plateforme a été capable de réaliser la même charge de travail en 55% du temps. Nous savons tous qu’AVX512 est rapide lorsqu’une tâche peut en tirer parti, et c’est certainement le cas ici.
Ensuite, nous avons également effectué quelques simulations de dynamique moléculaire. LAMMPS est un acronyme pour Large-scale Atomic/Molecular Massively Parallel Simulator, qui est un code classique de dynamique moléculaire avec un accent sur la modélisation des matériaux. Il fonctionne sur tous les types de plateformes, y compris les CPU et les GPU. La version CPU profite de l’AVX512 et est construite à partir des bibliothèques oneAPI.
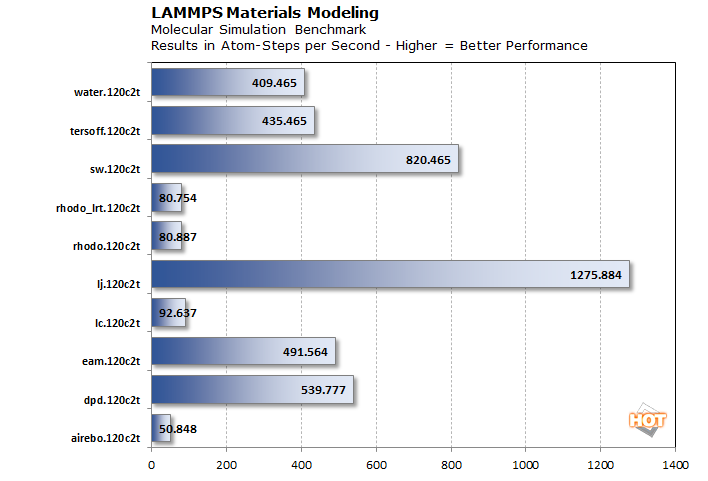
Malheureusement, ces résultats sont un peu hors contexte, car nous n’avons pas de matériel concurrent ni même de Xeon de génération précédente à notre disposition actuellement. Ce que nous pouvons vous dire, cependant, c’est que ces résultats sont à un point de pourcentage près par rapport à ce qu’Intel nous a montré lors de sa démonstration à Innovation 2022.
NAMD est un autre code de dynamique moléculaire parallèle conçu pour la simulation haute performance de grands systèmes biomoléculaires. Il peut évoluer jusqu’à et au-delà de 500 000 cœurs, ce qui signifie que les 120 cœurs dont nous disposons ici devraient être très sollicités. Tout comme LAMMPS, NAMD utilise également AVX512 aux soins de oneAPI. Plutôt qu’un graphique, nous obtenons un seul résultat : 3,25 nanosecondes par jour de simulation. Il semble que les scientifiques souhaiteraient que plusieurs de ces systèmes fonctionnent ensemble, ce qui explique pourquoi l’application peut s’étendre sur 500 000 cœurs de processeur ou plus. Il s’agit simplement d’une quantité impressionnante de mathématiques.
La dernière étape est le benchmark de reconnaissance d’image ResNet50. Il utilise la version 1.5 du modèle d’apprentissage automatique ResNet50, qui a subi quelques modifications par rapport au modèle original afin d’améliorer légèrement la reconnaissance et d’atténuer un goulot d’étranglement dans le sous-échantillonnage. En plus d’être plus précis, il devrait donc être un peu plus rapide que le modèle original. Il est important de noter tout cela lors de l’exécution d’un benchmark, car ces chiffres ne sont pas directement comparables à ceux de la version 1.
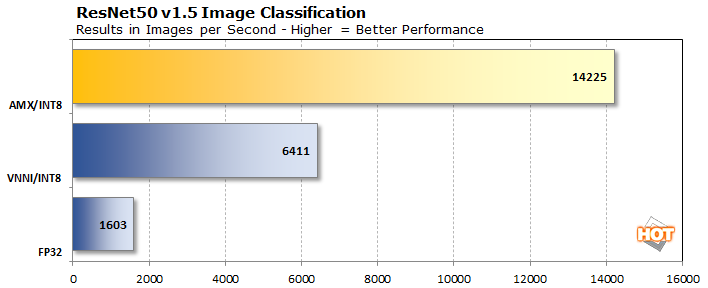
Les trois résultats ci-dessus font appel à des calculs en virgule flottante 32 bits et à des calculs en nombres entiers 8 bits, ces derniers étant plus rapides à exécuter en parallèle et présentant toujours une précision suffisante pour les tâches d’IA pour ne pas modifier les résultats de manière significative. Il suffit de faire ce changement et d’utiliser VNNI, le jeu d’instructions Vector Neural Network d’Intel, pour quadrupler nettement les performances dans ce benchmark. Mais lorsque le test passe à l’utilisation d’AMX, ou Advanced Matrix Extensions d’Intel, les performances sont à nouveau plus que doublées, offrant une augmentation de 9x des performances.
Test des assertions d’Intel Sapphire Rapids : Compression et charges de travail des bases de données
Maintenant que nous avons couvert les benchmarks inédits, passons à la confirmation des propres chiffres de benchmark d’Intel. Comme mentionné précédemment, nous n’avons pas eu l’accès physique à un serveur AMD Milan, similaire à celui qu’Intel a utilisé pour ses comparaisons avec les Sapphire Rapids, mais nous pouvons au moins valider si les affirmations d’Intel tiennent la route. Il y a suffisamment de données publiques disponibles sur le Web concernant les performances sur d’autres plates-formes, mais nous ne sommes pas à l’aise pour comparer notre propre travail contrôlé à d’autres, car il y a tellement de variables. Cela signifie que les affirmations d’Intel doivent, pour l’instant, s’appuyer sur leurs propres mérites.
Il y a deux catégories de ces tests : ceux qui nécessitent un second serveur comme client, et ceux qui n’en ont pas besoin. Nous allons nous concentrer sur ces derniers puisque nous avons dû utiliser l’environnement accessible à distance d’Intel comme client.
Nous allons commencer avec QATzip, la bibliothèque de compression accélérée d’Intel. Les technologies de compression permettent à l’Internet de fonctionner à pleine vitesse. Le texte, en particulier le HTML, le CSS et le JavaScript, peut être fortement compressé pour réduire les temps de téléchargement et permettre aux serveurs d’envoyer des données à autant de clients que possible tout en conservant la bande passante. Cependant, cette compression a souvent un coût, car elle nécessite de précieux cycles de CPU pour dégonfler les données dans un format Gzip standard ou dans des blocs LZ4 standard de données compressées contenues dans des cadres LZ4.
C’est là que le QAT de QATzip entre en jeu : La technologie d’assistance rapide d’Intel, qui est le nom de famille de plusieurs technologies d’accélérateurs Xeon, utilise deux méthodes pour accélérer le processus. La première est l’ISA-L d’Intel, ou Intelligent Storage Acceleration Library. Par rapport à la fonctionnalité Gzip de la bibliothèque de compression standard ZLIB, les performances promettent d’être plus de 15 fois plus rapides. La seconde consiste à utiliser le matériel d’accélération dédié d’Intel pour QATzip, ce qui, selon l’entreprise, devrait augmenter encore les performances.
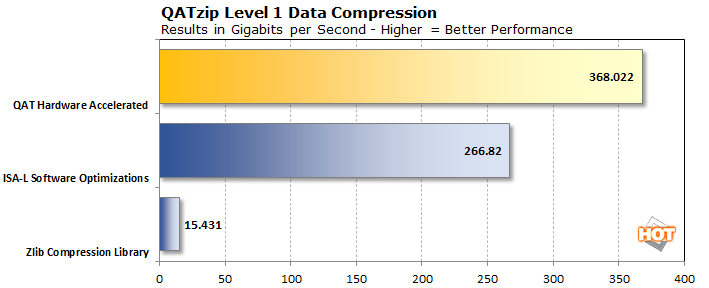
Rappelez-vous que dans les propres tests d’Intel, la paire de processeurs Milan 64 cœurs du système EPYC a en fait gagné avec la bibliothèque ISA-L d’Intel, et huit cœurs supplémentaires n’allaient probablement pas faire la différence. Cependant, l’utilisation de l’accélération Intel QAT intégrée à notre serveur a eu deux effets : non seulement les performances ont augmenté d’un peu moins de 40 %, mais le benchmark a indiqué qu’il n’utilisait pas les 120 cœurs. En fait, le serveur n’utilisait que quatre cœurs, ce que nous avons pu vérifier en utilisant la commande top dans une deuxième fenêtre de terminal SSH. Cela signifie que le reste des cœurs du CPU de notre système pouvait être occupé à d’autres tâches. En regardant les chiffres d’Intel, nous pouvons également voir que l’utilisation du matériel d’assistance rapide est assez rapide pour surpasser le système AMD EPYC de la génération actuelle, aussi.
Ensuite, il y a RocksDB, qui est un système de stockage d’indexation de données. Ses concurrents importants (et célèbres) sont Elasticsearch et OpenSearch d’Amazon. L’idée derrière ces systèmes d’indexation clé/valeur est de rendre d’énormes ensembles de données consultables avec une latence minimale. RocksDB a fait ses débuts en indexant les utilisateurs de Facebook et LinkedIn, les messages, les offres d’emploi, etc. Il est également utilisé comme méthode de stockage pour des bases de données SQL populaires comme MySQL et des bases de données NoSQL comme MongoDB et Redis. Ces outils sont importants pour permettre une recherche rapide sur Internet. Le QAT d’Intel accélère la compression des données et vise à accélérer la recherche et la découverte de documents.
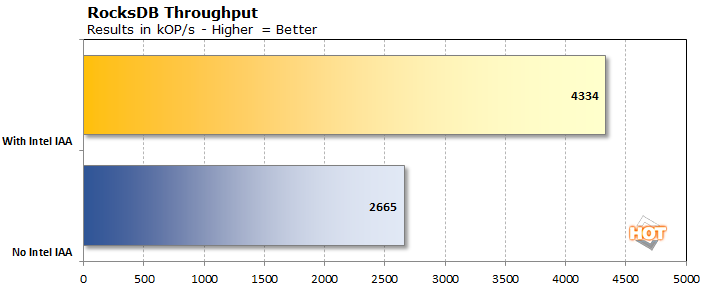
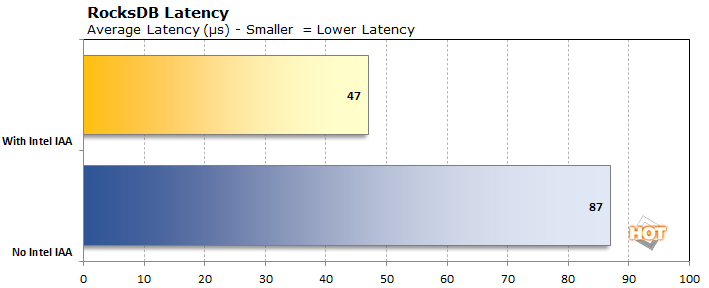
Le résultat “No Intel IAA” ci-dessus utilise l’algorithme de compression en temps réel Zstandard. La tâche est une charge de travail 80/20 (ce qui signifie que 80 % des opérations sont des opérations de lecture) dont la latence tourne autour de 100 microsecondes et qui peut gérer environ 2 500 kOP/s. En utilisant l’accélérateur d’analyse en mémoire (IAA) d’Intel, qui fait partie de la technologie Quick Assist, la latence a diminué de moitié, à 48 microsecondes, et le débit a atteint 4 291 kOP/s. Ces chiffres sont pratiquement identiques à ceux qu’Intel a publiés, ce qui montre que la QAT est vraiment pratique pour une autre charge de travail de serveur courante. L’IAA n’a pas accompli cela avec une empreinte de stockage énorme, non plus ; l’ensemble de données d’échantillon était autour de 43 Go sur le disque avec ZSTD, tandis que la version IAA était seulement légèrement plus grande à 44,6 Go. Bien sûr, ces données ont été chargées dans l’énorme 1 To de RAM du système pour maintenir les latences aussi faibles que possible, mais la persistance est obligatoire, sauf si vous voulez reconstruire un index à chaque redémarrage.
Ensuite, il est temps d’exécuter nos tests client/serveur, ce qui signifie pour nous une session SSH distante avec un autre serveur Sapphire Rapids. Ensuite, nous ferons le point sur tout ce que nous avons vu.
€